아파트분양가격동향
in Study on datavisualization
전국 신규 민간 아파트 분양가격 동향
다운로드 위치 : https://www.data.go.kr/dataset/3035522/fileData.do
전국 평균 분양가격(2013년 9월부터 2015년 8월까지) 주택도시보증공사_전국 평균 분양가격(2019년 12월) 두 개의 다른 데이터를 합치기
데이터 불러오기
import pandas as pd
df_last = pd.read_csv("data/주택도시보증공사_전국 평균 분양가격(2019년 12월).csv", encoding="cp949", engine="python")
#encoding으로 한글 깨지는걸 방지
# engine은 파이썬
df_last.shape
(4335, 5)
df_last.head()
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | |
|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 |
| 3 | 서울 | 전용면적 85㎡초과 102㎡이하 | 2015 | 10 | 5721 |
| 4 | 서울 | 전용면적 102㎡초과 | 2015 | 10 | 5879 |
df_last.tail()
# NaN는 결측치
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | |
|---|---|---|---|---|---|
| 4330 | 제주 | 전체 | 2019 | 12 | 3882 |
| 4331 | 제주 | 전용면적 60㎡이하 | 2019 | 12 | NaN |
| 4332 | 제주 | 전용면적 60㎡초과 85㎡이하 | 2019 | 12 | 3898 |
| 4333 | 제주 | 전용면적 85㎡초과 102㎡이하 | 2019 | 12 | NaN |
| 4334 | 제주 | 전용면적 102㎡초과 | 2019 | 12 | 3601 |
#%ls data
df_first = pd.read_csv("data/전국 평균 분양가격(2013년 9월부터 2015년 8월까지).csv",
encoding="cp949")
df_first.shape
(17, 22)
df_first.head()
| 지역 | 2013년12월 | 2014년1월 | 2014년2월 | 2014년3월 | 2014년4월 | 2014년5월 | 2014년6월 | 2014년7월 | 2014년8월 | ... | 2014년11월 | 2014년12월 | 2015년1월 | 2015년2월 | 2015년3월 | 2015년4월 | 2015년5월 | 2015년6월 | 2015년7월 | 2015년8월 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 18189 | 17925 | 17925 | 18016 | 18098 | 19446 | 18867 | 18742 | 19274 | ... | 20242 | 20269 | 20670 | 20670 | 19415 | 18842 | 18367 | 18374 | 18152 | 18443 |
| 1 | 부산 | 8111 | 8111 | 9078 | 8965 | 9402 | 9501 | 9453 | 9457 | 9411 | ... | 9208 | 9208 | 9204 | 9235 | 9279 | 9327 | 9345 | 9515 | 9559 | 9581 |
| 2 | 대구 | 8080 | 8080 | 8077 | 8101 | 8267 | 8274 | 8360 | 8360 | 8370 | ... | 8439 | 8253 | 8327 | 8416 | 8441 | 8446 | 8568 | 8542 | 8542 | 8795 |
| 3 | 인천 | 10204 | 10204 | 10408 | 10408 | 10000 | 9844 | 10058 | 9974 | 9973 | ... | 10020 | 10020 | 10017 | 9876 | 9876 | 9938 | 10551 | 10443 | 10443 | 10449 |
| 4 | 광주 | 6098 | 7326 | 7611 | 7346 | 7346 | 7523 | 7659 | 7612 | 7622 | ... | 7752 | 7748 | 7752 | 7756 | 7861 | 7914 | 7877 | 7881 | 8089 | 8231 |
5 rows × 22 columns
df_first.tail()
| 지역 | 2013년12월 | 2014년1월 | 2014년2월 | 2014년3월 | 2014년4월 | 2014년5월 | 2014년6월 | 2014년7월 | 2014년8월 | ... | 2014년11월 | 2014년12월 | 2015년1월 | 2015년2월 | 2015년3월 | 2015년4월 | 2015년5월 | 2015년6월 | 2015년7월 | 2015년8월 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 전북 | 6282 | 6281 | 5946 | 5966 | 6277 | 6306 | 6351 | 6319 | 6436 | ... | 6583 | 6583 | 6583 | 6583 | 6542 | 6551 | 6556 | 6601 | 6750 | 6580 |
| 13 | 전남 | 5678 | 5678 | 5678 | 5696 | 5736 | 5656 | 5609 | 5780 | 5685 | ... | 5768 | 5784 | 5784 | 5833 | 5825 | 5940 | 6050 | 6243 | 6286 | 6289 |
| 14 | 경북 | 6168 | 6168 | 6234 | 6317 | 6412 | 6409 | 6554 | 6556 | 6563 | ... | 6881 | 6989 | 6992 | 6953 | 6997 | 7006 | 6966 | 6887 | 7035 | 7037 |
| 15 | 경남 | 6473 | 6485 | 6502 | 6610 | 6599 | 6610 | 6615 | 6613 | 6606 | ... | 7125 | 7332 | 7592 | 7588 | 7668 | 7683 | 7717 | 7715 | 7723 | 7665 |
| 16 | 제주 | 7674 | 7900 | 7900 | 7900 | 7900 | 7900 | 7914 | 7914 | 7914 | ... | 7724 | 7739 | 7739 | 7739 | 7826 | 7285 | 7285 | 7343 | 7343 | 7343 |
5 rows × 22 columns
데이터 요약하기
df_last.info()
# 분양가격은 결측치도 있고 object형으로 되어있다.
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
dtypes: int64(2), object(3)
memory usage: 169.5+ KB
결측치 보기
df_last.isnull()
# null값은 true
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | |
|---|---|---|---|---|---|
| 0 | False | False | False | False | False |
| 1 | False | False | False | False | False |
| 2 | False | False | False | False | False |
| 3 | False | False | False | False | False |
| 4 | False | False | False | False | False |
| ... | ... | ... | ... | ... | ... |
| 4330 | False | False | False | False | False |
| 4331 | False | False | False | False | True |
| 4332 | False | False | False | False | False |
| 4333 | False | False | False | False | True |
| 4334 | False | False | False | False | False |
4335 rows × 5 columns
# 결측치 수 구하기
df_last.isnull().sum()
지역명 0
규모구분 0
연도 0
월 0
분양가격(㎡) 277
dtype: int64
데이터 타입 변경
# object인 분양가격을 float형태로 바꿔주기(새로운 분양가격 칼럼을 만들어줌)
df_last["분양가격"] = pd.to_numeric(df_last["분양가격(㎡)"], errors='coerce')
df_last.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
5 분양가격 3957 non-null float64
dtypes: float64(1), int64(2), object(3)
memory usage: 203.3+ KB
두 파일 단위를 맞춰주기
# df_last 분양가격에 3.3을 곱해서 평당분양가격을 맞추어주기
df_last["평당분양가격"] = df_last["분양가격"] * 3.3
df_last.head()
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | |
|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 |
| 3 | 서울 | 전용면적 85㎡초과 102㎡이하 | 2015 | 10 | 5721 | 5721.0 | 18879.3 |
| 4 | 서울 | 전용면적 102㎡초과 | 2015 | 10 | 5879 | 5879.0 | 19400.7 |
분양가격 요약
df_last.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4335 entries, 0 to 4334
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 지역명 4335 non-null object
1 규모구분 4335 non-null object
2 연도 4335 non-null int64
3 월 4335 non-null int64
4 분양가격(㎡) 4058 non-null object
5 분양가격 3957 non-null float64
6 평당분양가격 3957 non-null float64
dtypes: float64(2), int64(2), object(3)
memory usage: 237.2+ KB
# object형 describe
df_last["분양가격(㎡)"].describe()
#df_last.shape
count 4058
unique 1753
top 2221
freq 17
Name: 분양가격(㎡), dtype: object
# float형 describe
df_last["분양가격"].describe()
count 3957.000000
mean 3238.128633
std 1264.309933
min 1868.000000
25% 2441.000000
50% 2874.000000
75% 3561.000000
max 12728.000000
Name: 분양가격, dtype: float64
규모구분칼럼을 전용면적 칼럼명 변경
df_last["규모구분"].unique()
array(['전체', '전용면적 60㎡이하', '전용면적 60㎡초과 85㎡이하', '전용면적 85㎡초과 102㎡이하',
'전용면적 102㎡초과'], dtype=object)
df_last["전용면적"] = df_last["규모구분"].str.replace("전용면적", "")
# 앞에 전용면적 text가 사라진다. > 칼럼명 전용면적을 만든다.
df_last["전용면적"] = df_last["전용면적"].str.replace("초과","~")
# 초과text가 사라지고 ~을 넣어준다.
df_last["전용면적"] = df_last["전용면적"].str.replace("이하","")
#이하 text가 사라진다.
df_last["전용면적"].str.replace(" ", "").str.strip()
# " "을 ""으로 바꾸고 strip을 써서 앞 뒤 공백을 없애기
0 전체
1 60㎡
2 60㎡~85㎡
3 85㎡~102㎡
4 102㎡~
...
4330 전체
4331 60㎡
4332 60㎡~85㎡
4333 85㎡~102㎡
4334 102㎡~
Name: 전용면적, Length: 4335, dtype: object
df_last
| 지역명 | 규모구분 | 연도 | 월 | 분양가격(㎡) | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 전체 | 2015 | 10 | 5841 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 전용면적 60㎡이하 | 2015 | 10 | 5652 | 5652.0 | 18651.6 | 60㎡ |
| 2 | 서울 | 전용면적 60㎡초과 85㎡이하 | 2015 | 10 | 5882 | 5882.0 | 19410.6 | 60㎡~ 85㎡ |
| 3 | 서울 | 전용면적 85㎡초과 102㎡이하 | 2015 | 10 | 5721 | 5721.0 | 18879.3 | 85㎡~ 102㎡ |
| 4 | 서울 | 전용면적 102㎡초과 | 2015 | 10 | 5879 | 5879.0 | 19400.7 | 102㎡~ |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4330 | 제주 | 전체 | 2019 | 12 | 3882 | 3882.0 | 12810.6 | 전체 |
| 4331 | 제주 | 전용면적 60㎡이하 | 2019 | 12 | NaN | NaN | NaN | 60㎡ |
| 4332 | 제주 | 전용면적 60㎡초과 85㎡이하 | 2019 | 12 | 3898 | 3898.0 | 12863.4 | 60㎡~ 85㎡ |
| 4333 | 제주 | 전용면적 85㎡초과 102㎡이하 | 2019 | 12 | NaN | NaN | NaN | 85㎡~ 102㎡ |
| 4334 | 제주 | 전용면적 102㎡초과 | 2019 | 12 | 3601 | 3601.0 | 11883.3 | 102㎡~ |
4335 rows × 8 columns
# 규모규분, 분양가격(㎡) 칼럼을 없애기 drop이용
df_last = df_last.drop(["규모구분","분양가격(㎡)"], axis=1)
#axis=1로 해야지 칼럼이 제거된다.(중요) 기본값이 0이다.
df_last
| 지역명 | 연도 | 월 | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 2015 | 10 | 5652.0 | 18651.6 | 60㎡ |
| 2 | 서울 | 2015 | 10 | 5882.0 | 19410.6 | 60㎡~ 85㎡ |
| 3 | 서울 | 2015 | 10 | 5721.0 | 18879.3 | 85㎡~ 102㎡ |
| 4 | 서울 | 2015 | 10 | 5879.0 | 19400.7 | 102㎡~ |
| ... | ... | ... | ... | ... | ... | ... |
| 4330 | 제주 | 2019 | 12 | 3882.0 | 12810.6 | 전체 |
| 4331 | 제주 | 2019 | 12 | NaN | NaN | 60㎡ |
| 4332 | 제주 | 2019 | 12 | 3898.0 | 12863.4 | 60㎡~ 85㎡ |
| 4333 | 제주 | 2019 | 12 | NaN | NaN | 85㎡~ 102㎡ |
| 4334 | 제주 | 2019 | 12 | 3601.0 | 11883.3 | 102㎡~ |
4335 rows × 6 columns
groupby로 데이터전처리
# 지역명이 같은거끼리 묶고, 평당분양가격의 평균값을 계산한다.
df_last.groupby(["지역명"])["평당분양가격"].mean()
지역명
강원 7890.750000
경기 13356.895200
경남 9268.778138
경북 8376.536515
광주 9951.535821
대구 11980.895455
대전 10253.333333
부산 12087.121200
서울 23599.976400
세종 9796.516456
울산 10014.902013
인천 11915.320732
전남 7565.316532
전북 7724.235484
제주 11241.276712
충남 8233.651883
충북 7634.655600
Name: 평당분양가격, dtype: float64
# 전용면적 묶고, 평당분양가격의 평균값을 계산한다.
df_last.groupby(["전용면적"])["평당분양가격"].mean()
전용면적
102㎡~ 11517.705634
60㎡ 10375.137421
60㎡~ 85㎡ 10271.040071
85㎡~ 102㎡ 11097.599573
전체 10276.086207
Name: 평당분양가격, dtype: float64
df_last.groupby(["지역명","전용면적"])["평당분양가격"].mean()
# 처음에 지역명으로 묶고, 두번째로 전용면적으로 묶는다.
지역명 전용면적
강원 102㎡~ 8311.380000
60㎡ 7567.098000
60㎡~ 85㎡ 7485.588000
85㎡~ 102㎡ 8749.557143
전체 7477.536000
...
충북 102㎡~ 8195.352000
60㎡ 7103.118000
60㎡~ 85㎡ 7264.488000
85㎡~ 102㎡ 8391.306000
전체 7219.014000
Name: 평당분양가격, Length: 85, dtype: float64
df_last.groupby(["지역명","전용면적"])["평당분양가격"].mean().unstack()
# unstack을 이용하면 두번째로 있는 전용면적이 칼럼값으로 간다.
| 전용면적 | 102㎡~ | 60㎡ | 60㎡~ 85㎡ | 85㎡~ 102㎡ | 전체 |
|---|---|---|---|---|---|
| 지역명 | |||||
| 강원 | 8311.380000 | 7567.098000 | 7485.588000 | 8749.557143 | 7477.536000 |
| 경기 | 14771.790000 | 13251.744000 | 12523.566000 | 13677.774000 | 12559.602000 |
| 경남 | 10358.363265 | 8689.175000 | 8618.676000 | 10017.612000 | 8658.672000 |
| 경북 | 9157.302000 | 7883.172000 | 8061.372000 | 8773.814634 | 8078.532000 |
| 광주 | 11041.532432 | 9430.666667 | 9910.692000 | 9296.100000 | 9903.630000 |
| 대구 | 13087.338000 | 11992.068000 | 11778.690000 | 11140.642857 | 11771.298000 |
| 대전 | 14876.871429 | 9176.475000 | 9711.372000 | 9037.430769 | 9786.018000 |
| 부산 | 13208.250000 | 11353.782000 | 11864.820000 | 12072.588000 | 11936.166000 |
| 서울 | 23446.038000 | 23212.794000 | 22786.830000 | 25943.874000 | 22610.346000 |
| 세종 | 10106.976000 | 9323.927027 | 9775.458000 | 9847.926000 | 9805.422000 |
| 울산 | 9974.448000 | 9202.106897 | 10502.531707 | 8861.007692 | 10492.712195 |
| 인천 | 14362.030435 | 11241.318000 | 11384.406000 | 11527.560000 | 11257.026000 |
| 전남 | 8168.490000 | 7210.170000 | 7269.240000 | 7908.862500 | 7283.562000 |
| 전북 | 8193.570000 | 7609.932000 | 7271.352000 | 8275.781250 | 7292.604000 |
| 제주 | 10522.787234 | 14022.221053 | 10621.314000 | 10709.082353 | 10784.994000 |
| 충남 | 8689.169388 | 7911.156000 | 7818.954000 | 9120.045000 | 7815.324000 |
| 충북 | 8195.352000 | 7103.118000 | 7264.488000 | 8391.306000 | 7219.014000 |
df_last.groupby(["지역명","전용면적"])["평당분양가격"].mean().unstack().round()
# round를 이용하면 소수점 한자리로 바꿀 수 있다.
| 전용면적 | 102㎡~ | 60㎡ | 60㎡~ 85㎡ | 85㎡~ 102㎡ | 전체 |
|---|---|---|---|---|---|
| 지역명 | |||||
| 강원 | 8311.0 | 7567.0 | 7486.0 | 8750.0 | 7478.0 |
| 경기 | 14772.0 | 13252.0 | 12524.0 | 13678.0 | 12560.0 |
| 경남 | 10358.0 | 8689.0 | 8619.0 | 10018.0 | 8659.0 |
| 경북 | 9157.0 | 7883.0 | 8061.0 | 8774.0 | 8079.0 |
| 광주 | 11042.0 | 9431.0 | 9911.0 | 9296.0 | 9904.0 |
| 대구 | 13087.0 | 11992.0 | 11779.0 | 11141.0 | 11771.0 |
| 대전 | 14877.0 | 9176.0 | 9711.0 | 9037.0 | 9786.0 |
| 부산 | 13208.0 | 11354.0 | 11865.0 | 12073.0 | 11936.0 |
| 서울 | 23446.0 | 23213.0 | 22787.0 | 25944.0 | 22610.0 |
| 세종 | 10107.0 | 9324.0 | 9775.0 | 9848.0 | 9805.0 |
| 울산 | 9974.0 | 9202.0 | 10503.0 | 8861.0 | 10493.0 |
| 인천 | 14362.0 | 11241.0 | 11384.0 | 11528.0 | 11257.0 |
| 전남 | 8168.0 | 7210.0 | 7269.0 | 7909.0 | 7284.0 |
| 전북 | 8194.0 | 7610.0 | 7271.0 | 8276.0 | 7293.0 |
| 제주 | 10523.0 | 14022.0 | 10621.0 | 10709.0 | 10785.0 |
| 충남 | 8689.0 | 7911.0 | 7819.0 | 9120.0 | 7815.0 |
| 충북 | 8195.0 | 7103.0 | 7264.0 | 8391.0 | 7219.0 |
#연도,지역명으로 평당분양가격 평균 구하기
g = df_last.groupby(["연도","지역명"])["평당분양가격"].mean()
g
연도 지역명
2015 강원 7188.060000
경기 11060.940000
경남 8459.220000
경북 7464.160000
광주 7916.700000
...
2019 전남 8219.275862
전북 8532.260000
제주 11828.469231
충남 8748.840000
충북 7970.875000
Name: 평당분양가격, Length: 85, dtype: float64
df_last.groupby(["연도","지역명"])["평당분양가격"].mean().unstack().T
#unstack으로 지역명을 칼럼으로 보내고, T(transpose)로 칼럼과 행값을 바꿔준다.
| 연도 | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|
| 지역명 | |||||
| 강원 | 7188.060 | 7162.903846 | 7273.560000 | 8219.255000 | 8934.475000 |
| 경기 | 11060.940 | 11684.970000 | 12304.980000 | 14258.420000 | 15665.540000 |
| 경남 | 8459.220 | 8496.730000 | 8786.760000 | 9327.670000 | 10697.615789 |
| 경북 | 7464.160 | 7753.405000 | 8280.800000 | 8680.776923 | 9050.250000 |
| 광주 | 7916.700 | 9190.683333 | 9613.977551 | 9526.953333 | 12111.675000 |
| 대구 | 9018.900 | 10282.030000 | 12206.700000 | 12139.252632 | 14081.650000 |
| 대전 | 8190.600 | 8910.733333 | 9957.158491 | 10234.106667 | 12619.200000 |
| 부산 | 10377.400 | 10743.535000 | 11560.680000 | 12889.965000 | 13537.865000 |
| 서울 | 20315.680 | 21753.435000 | 21831.060000 | 23202.245000 | 28286.830000 |
| 세종 | 8765.020 | 8857.805000 | 9132.505556 | 10340.463158 | 11299.394118 |
| 울산 | 9367.600 | 9582.574138 | 10666.935714 | 10241.400000 | 10216.250000 |
| 인천 | 10976.020 | 11099.055000 | 11640.600000 | 11881.532143 | 13249.775000 |
| 전남 | 6798.880 | 6936.600000 | 7372.920000 | 7929.845000 | 8219.275862 |
| 전북 | 7110.400 | 6906.625000 | 7398.973585 | 8174.595000 | 8532.260000 |
| 제주 | 7951.075 | 9567.480000 | 12566.730000 | 11935.968000 | 11828.469231 |
| 충남 | 7689.880 | 7958.225000 | 8198.422222 | 8201.820000 | 8748.840000 |
| 충북 | 6828.800 | 7133.335000 | 7473.120000 | 8149.295000 | 7970.875000 |
pivot table로 데이터 전처리
#aggfunc으로 mean, sum같은 계산이 가능하다.
pd.pivot_table(df_last, index=["지역명"], values=["평당분양가격"], aggfunc="mean")
| 평당분양가격 | |
|---|---|
| 지역명 | |
| 강원 | 7890.750000 |
| 경기 | 13356.895200 |
| 경남 | 9268.778138 |
| 경북 | 8376.536515 |
| 광주 | 9951.535821 |
| 대구 | 11980.895455 |
| 대전 | 10253.333333 |
| 부산 | 12087.121200 |
| 서울 | 23599.976400 |
| 세종 | 9796.516456 |
| 울산 | 10014.902013 |
| 인천 | 11915.320732 |
| 전남 | 7565.316532 |
| 전북 | 7724.235484 |
| 제주 | 11241.276712 |
| 충남 | 8233.651883 |
| 충북 | 7634.655600 |
# 전용면적 그룹으로 평당분양가격 평균 구하기
pd.pivot_table(df_last, index="전용면적", values="평당분양가격", aggfunc="mean")
| 평당분양가격 | |
|---|---|
| 전용면적 | |
| 102㎡~ | 11517.705634 |
| 60㎡ | 10375.137421 |
| 60㎡~ 85㎡ | 10271.040071 |
| 85㎡~ 102㎡ | 11097.599573 |
| 전체 | 10276.086207 |
# 지역명,전용면적 그룹으로 평당분양가격 평균 구하기
df_last.pivot_table(index=["전용면적","지역명"], values="평당분양가격", aggfunc="mean")
| 평당분양가격 | ||
|---|---|---|
| 전용면적 | 지역명 | |
| 102㎡~ | 강원 | 8311.380000 |
| 경기 | 14771.790000 | |
| 경남 | 10358.363265 | |
| 경북 | 9157.302000 | |
| 광주 | 11041.532432 | |
| ... | ... | ... |
| 전체 | 전남 | 7283.562000 |
| 전북 | 7292.604000 | |
| 제주 | 10784.994000 | |
| 충남 | 7815.324000 | |
| 충북 | 7219.014000 |
85 rows × 1 columns
# 지역명,전용면적 그룹으로 평당분양가격 평균 구하기 (unstack으로 지역명 칼럼으로가게하기)
df_last.pivot_table(index="전용면적",columns="지역명", values="평당분양가격", aggfunc="mean").round()
| 지역명 | 강원 | 경기 | 경남 | 경북 | 광주 | 대구 | 대전 | 부산 | 서울 | 세종 | 울산 | 인천 | 전남 | 전북 | 제주 | 충남 | 충북 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 전용면적 | |||||||||||||||||
| 102㎡~ | 8311.0 | 14772.0 | 10358.0 | 9157.0 | 11042.0 | 13087.0 | 14877.0 | 13208.0 | 23446.0 | 10107.0 | 9974.0 | 14362.0 | 8168.0 | 8194.0 | 10523.0 | 8689.0 | 8195.0 |
| 60㎡ | 7567.0 | 13252.0 | 8689.0 | 7883.0 | 9431.0 | 11992.0 | 9176.0 | 11354.0 | 23213.0 | 9324.0 | 9202.0 | 11241.0 | 7210.0 | 7610.0 | 14022.0 | 7911.0 | 7103.0 |
| 60㎡~ 85㎡ | 7486.0 | 12524.0 | 8619.0 | 8061.0 | 9911.0 | 11779.0 | 9711.0 | 11865.0 | 22787.0 | 9775.0 | 10503.0 | 11384.0 | 7269.0 | 7271.0 | 10621.0 | 7819.0 | 7264.0 |
| 85㎡~ 102㎡ | 8750.0 | 13678.0 | 10018.0 | 8774.0 | 9296.0 | 11141.0 | 9037.0 | 12073.0 | 25944.0 | 9848.0 | 8861.0 | 11528.0 | 7909.0 | 8276.0 | 10709.0 | 9120.0 | 8391.0 |
| 전체 | 7478.0 | 12560.0 | 8659.0 | 8079.0 | 9904.0 | 11771.0 | 9786.0 | 11936.0 | 22610.0 | 9805.0 | 10493.0 | 11257.0 | 7284.0 | 7293.0 | 10785.0 | 7815.0 | 7219.0 |
# 연도, 지역명으로 평당분양가격으로 평균 구하기
p = pd.pivot_table(df_last, index=["연도","지역명"], values="평당분양가격")
p.loc[2017] # loc는 행을 기준으로 가져온다.
# 2017년 데이터만 볼 수 있다.
| 평당분양가격 | |
|---|---|
| 지역명 | |
| 강원 | 7273.560000 |
| 경기 | 12304.980000 |
| 경남 | 8786.760000 |
| 경북 | 8280.800000 |
| 광주 | 9613.977551 |
| 대구 | 12206.700000 |
| 대전 | 9957.158491 |
| 부산 | 11560.680000 |
| 서울 | 21831.060000 |
| 세종 | 9132.505556 |
| 울산 | 10666.935714 |
| 인천 | 11640.600000 |
| 전남 | 7372.920000 |
| 전북 | 7398.973585 |
| 제주 | 12566.730000 |
| 충남 | 8198.422222 |
| 충북 | 7473.120000 |
최근 데이터 시각화 하기
#지역명으로 분양가격의 평균 구하고 선그래프
#한글 폰트 사용하기
import matplotlib.pyplot as plt
plt.rc("font", family="Malgun Gothic")
g = df_last.groupby(["지역명"])["평당분양가격"].mean().sort_values(ascending=False)
#sort_values는 기본값 오름차순
#ascending=False는 내림차순
#g.plot(kind="bar")
g.plot.bar(rot=0, figsize=(10, 3))
#rot=0 글씨 똑바로 보기
<matplotlib.axes._subplots.AxesSubplot at 0x171e4779a00>
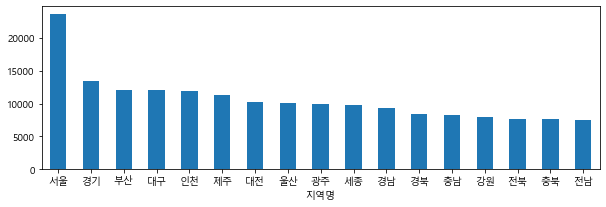
#전용면적당 평당분양가격
df_last.groupby(["전용면적"])["평당분양가격"].mean().plot.bar(rot=0)
<matplotlib.axes._subplots.AxesSubplot at 0x171e4f31af0>
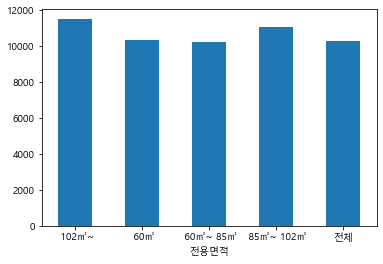
# 연도별 분양가격의 평균 막대그래프
df_last.groupby(["연도"])["평당분양가격"].mean().plot()
<matplotlib.axes._subplots.AxesSubplot at 0x171e4f38130>
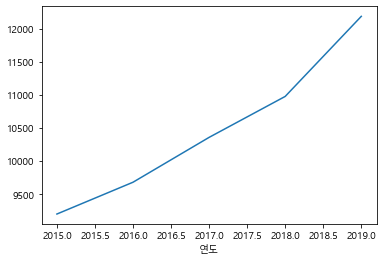
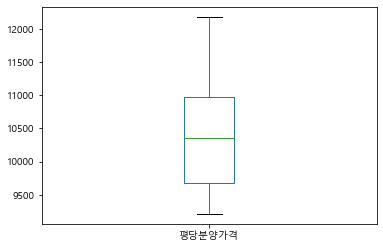
# boxplot으로 연도별 평당분양가격 확인
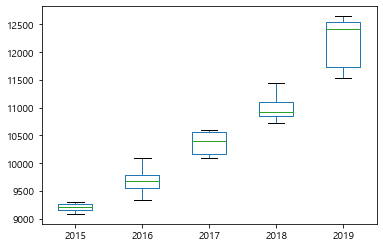
df_last.pivot_table(index="연도", values="평당분양가격").plot.box()
<matplotlib.axes._subplots.AxesSubplot at 0x171e4ff6310>
# 연도에 따른 전용면적
df_last.pivot_table(index="월", columns="연도", values="평당분양가격").plot.box()
<matplotlib.axes._subplots.AxesSubplot at 0x171e5052370>
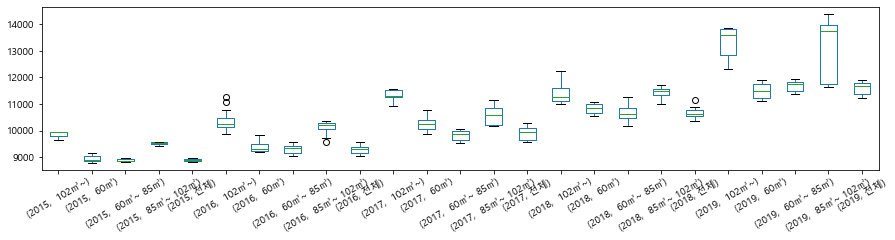
p = df_last.pivot_table(index="월", columns=["연도","전용면적"], values="평당분양가격")
p.plot.box(figsize=(15, 3), rot=30)
<matplotlib.axes._subplots.AxesSubplot at 0x171e5058c70>
p.plot.bar(figsize=(15, 3), rot=30)
<matplotlib.axes._subplots.AxesSubplot at 0x171e631b460>
p = df_last.pivot_table(index="연도", columns="월", values="평당분양가격")
p.plot.line(figsize=(15, 3), rot=30)
#분양가가 꾸준히 상승한것을 알 수 있다.
<matplotlib.axes._subplots.AxesSubplot at 0x171e67035b0>
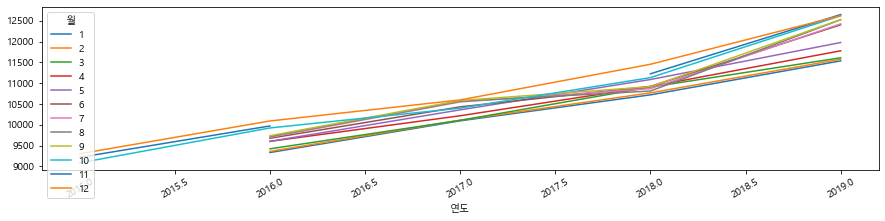
# seaborn으로 시각화
import seaborn as sns
plt.figure(figsize=(10,3))
sns.barplot(data=df_last, x="지역명", y="평당분양가격", #기본값 평균
ci = None) # ci는 신뢰구간,sd= 표준편차, 기본값 95
<matplotlib.axes._subplots.AxesSubplot at 0x171e7a58340>
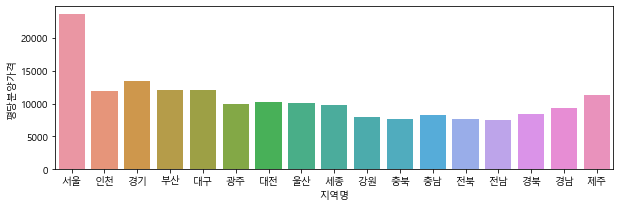
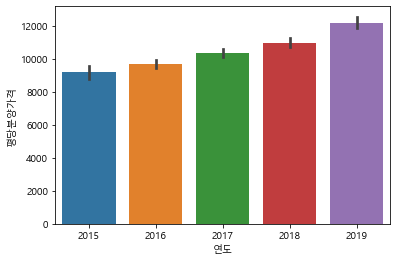
#barplot으로 연도별 평당분양가격 그리기
sns.barplot(data=df_last, x="연도", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171e7af6fa0>
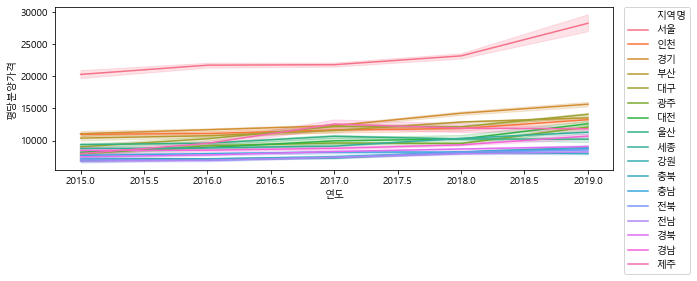
# linplot으로 연도별 평당분양가격 그리기
plt.figure(figsize=(10,3))
sns.lineplot(data=df_last, x="연도", y="평당분양가격", hue="지역명")
#hue로 지역명에 따라 다른색으로 표현
#legend(범례값을 밖에 그리는 법)
plt.legend(bbox_to_anchor=(1.02, 1), loc=2, borderaxespad=0.)
<matplotlib.legend.Legend at 0x171e7b5e7c0>
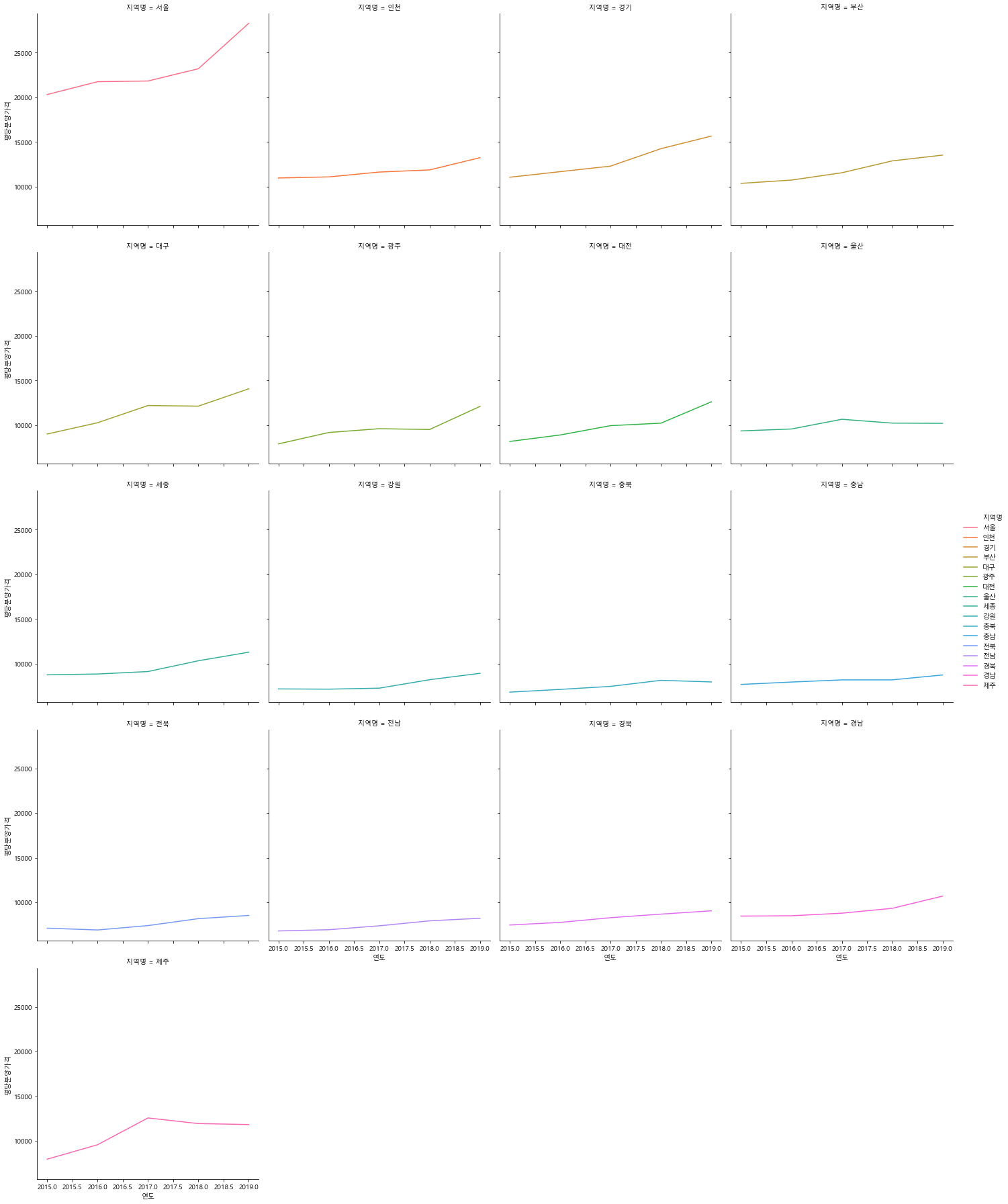
#relplot는 col, coloption을 쓸 수 있다.
sns.relplot(data=df_last, x="연도", y="평당분양가격",
kind="line", hue="지역명", col="지역명", col_wrap=4, ci=None)
#col_wrap 4줄씩 지역명에 따라 그래프를 그려준다.
# relplot는 기본값 scatter이다.
<seaborn.axisgrid.FacetGrid at 0x171e7cdfb80>
#catplot으로 그리기 col, col_wrap 가능하다.
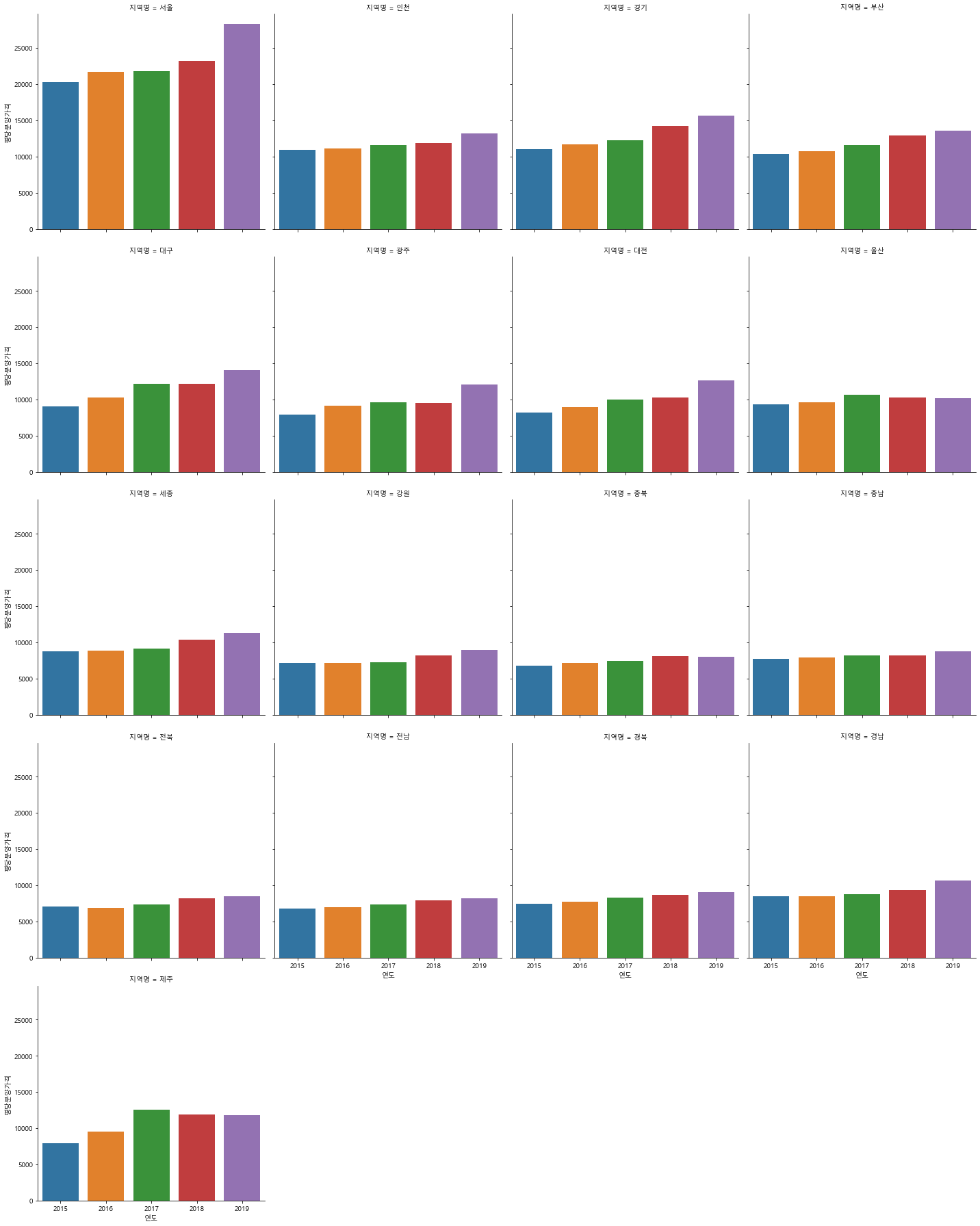
sns.catplot(data=df_last, x="연도", y="평당분양가격",
kind="bar", ci=None, col="지역명", col_wrap=4)
<seaborn.axisgrid.FacetGrid at 0x171e9c79e20>
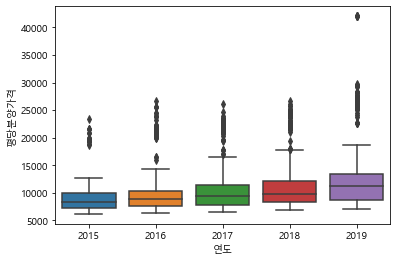
#boxplot과 violinplot
sns.boxplot(data=df_last, x="연도", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171ec007220>
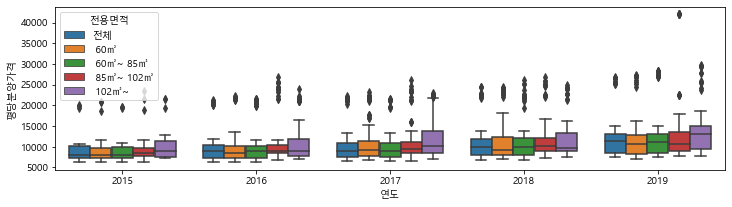
# hue옵션을 주어 전용면적별로 다르게 표시해 보기
plt.figure(figsize=(12, 3))
sns.boxplot(data=df_last, x="연도", y="평당분양가격", hue="전용면적")
<matplotlib.axes._subplots.AxesSubplot at 0x171ea6bc6d0>
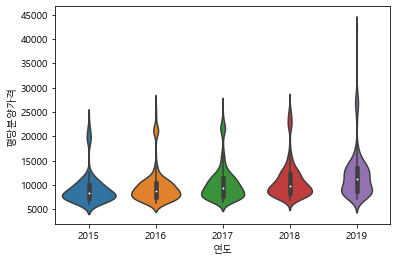
# 연도별 평당분양가격을 violinplot으로 그려보기
sns.violinplot(data=df_last, x="연도", y="평당분양가격")
# 데이터가 어디에 많은지 파악할 수 있다.
<matplotlib.axes._subplots.AxesSubplot at 0x171ec2dea90>
# lmplot과 swarmplot
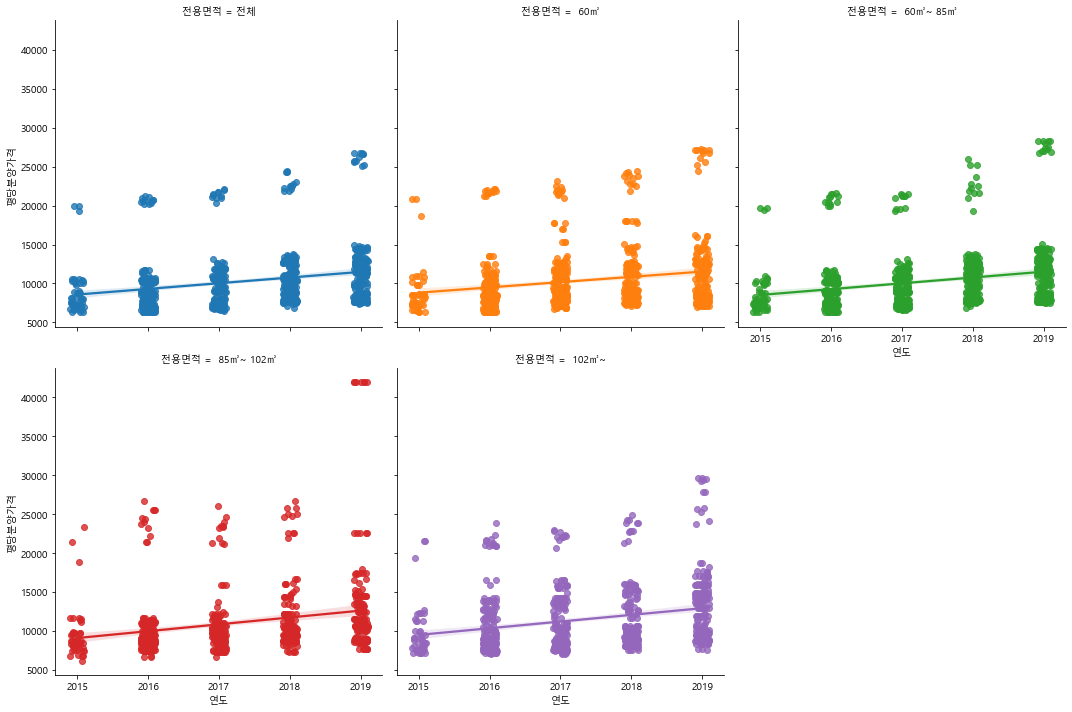
sns.lmplot(data=df_last, x="연도", y="평당분양가격", hue="전용면적",
col="전용면적", col_wrap=3, x_jitter=.1)
<seaborn.axisgrid.FacetGrid at 0x171ec2b79d0>
# 연도별 평당분양가격을 swarmplot 으로 그려보기
# swarmplot은 범주형(카테고리) 데이터의 산점도를 표현하기에 적합
#plt.figure(figsize=(15, 3))
#sns.swarmplot(data=df_last, x="연도", y="평당분양가격", hue="전용면적")
#이상치 보기
df_last["평당분양가격"].describe()
count 3957.000000
mean 10685.824488
std 4172.222780
min 6164.400000
25% 8055.300000
50% 9484.200000
75% 11751.300000
max 42002.400000
Name: 평당분양가격, dtype: float64
max_price = df_last["평당분양가격"].max()
max_price
42002.399999999994
df_last[df_last["평당분양가격"] == max_price]
| 지역명 | 연도 | 월 | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|
| 3743 | 서울 | 2019 | 6 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
| 3828 | 서울 | 2019 | 7 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
| 3913 | 서울 | 2019 | 8 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
| 3998 | 서울 | 2019 | 9 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
| 4083 | 서울 | 2019 | 10 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
| 4168 | 서울 | 2019 | 11 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
| 4253 | 서울 | 2019 | 12 | 12728.0 | 42002.4 | 85㎡~ 102㎡ |
수치데이터 히스토그램 그리기
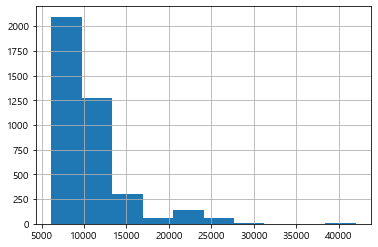
h = df_last["평당분양가격"].hist(bins=10) # bins는 몇개의 구간에 담을것인가?
# 결측치 없는 데이터 가져오기 loc이용
price = df_last.loc[df_last["평당분양가격"].notnull(),"평당분양가격"]
price
0 19275.3
1 18651.6
2 19410.6
3 18879.3
4 19400.7
...
4327 10114.5
4328 10715.1
4330 12810.6
4332 12863.4
4334 11883.3
Name: 평당분양가격, Length: 3957, dtype: float64
# distplot으로 평당 분양가격을 표현
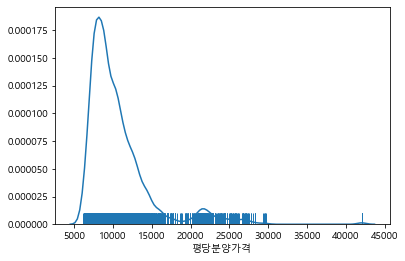
sns.distplot(price, hist=False, rug=True)
<matplotlib.axes._subplots.AxesSubplot at 0x171ec7e0910>
# subplot 으로 표현해보기 (산마루)
#g = sns.FacetGrid(df_last, row="지역명",
# height=1.7, aspect=4,)
#g.map(sns.distplot, "평당분양가격", hist=False, rug=True);
# pairplot
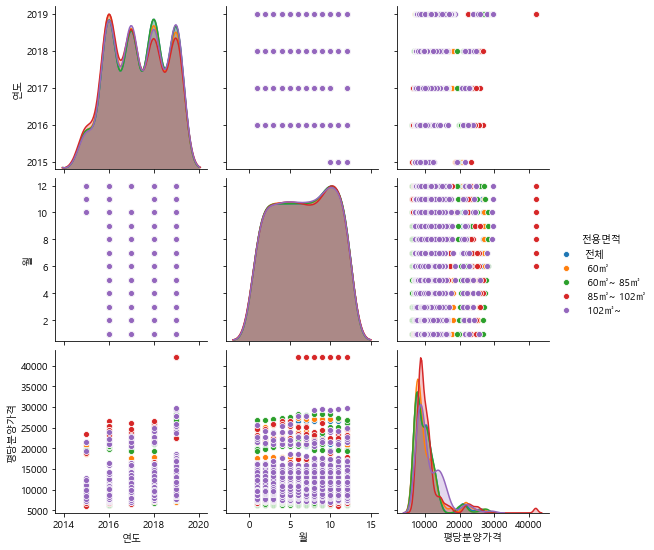
df_last_notnull = df_last.loc[df_last["평당분양가격"].notnull(),
["연도","월","평당분양가격","지역명","전용면적"]]
sns.pairplot(df_last_notnull, hue="전용면적")
<seaborn.axisgrid.PairGrid at 0x171edd96c40>
#전용면적 별로 value_counts를 사용하여 데이터를 집계
df_last["전용면적"].value_counts()
102㎡~ 867
60㎡~ 85㎡ 867
85㎡~ 102㎡ 867
전체 867
60㎡ 867
Name: 전용면적, dtype: int64
2015년 8월 이전 데이터 보기
pd.options.display.max_columns = 100 # 칼럼 전체보기
df_first.head()
| 지역 | 2013년12월 | 2014년1월 | 2014년2월 | 2014년3월 | 2014년4월 | 2014년5월 | 2014년6월 | 2014년7월 | 2014년8월 | 2014년9월 | 2014년10월 | 2014년11월 | 2014년12월 | 2015년1월 | 2015년2월 | 2015년3월 | 2015년4월 | 2015년5월 | 2015년6월 | 2015년7월 | 2015년8월 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 서울 | 18189 | 17925 | 17925 | 18016 | 18098 | 19446 | 18867 | 18742 | 19274 | 19404 | 19759 | 20242 | 20269 | 20670 | 20670 | 19415 | 18842 | 18367 | 18374 | 18152 | 18443 |
| 1 | 부산 | 8111 | 8111 | 9078 | 8965 | 9402 | 9501 | 9453 | 9457 | 9411 | 9258 | 9110 | 9208 | 9208 | 9204 | 9235 | 9279 | 9327 | 9345 | 9515 | 9559 | 9581 |
| 2 | 대구 | 8080 | 8080 | 8077 | 8101 | 8267 | 8274 | 8360 | 8360 | 8370 | 8449 | 8403 | 8439 | 8253 | 8327 | 8416 | 8441 | 8446 | 8568 | 8542 | 8542 | 8795 |
| 3 | 인천 | 10204 | 10204 | 10408 | 10408 | 10000 | 9844 | 10058 | 9974 | 9973 | 9973 | 10016 | 10020 | 10020 | 10017 | 9876 | 9876 | 9938 | 10551 | 10443 | 10443 | 10449 |
| 4 | 광주 | 6098 | 7326 | 7611 | 7346 | 7346 | 7523 | 7659 | 7612 | 7622 | 7802 | 7707 | 7752 | 7748 | 7752 | 7756 | 7861 | 7914 | 7877 | 7881 | 8089 | 8231 |
# 결측치 확인
df_first.isnull().sum()
# 0이면 결측치가 없는것
지역 0
2013년12월 0
2014년1월 0
2014년2월 0
2014년3월 0
2014년4월 0
2014년5월 0
2014년6월 0
2014년7월 0
2014년8월 0
2014년9월 0
2014년10월 0
2014년11월 0
2014년12월 0
2015년1월 0
2015년2월 0
2015년3월 0
2015년4월 0
2015년5월 0
2015년6월 0
2015년7월 0
2015년8월 0
dtype: int64
df_last.head()
| 지역명 | 연도 | 월 | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 5841.0 | 19275.3 | 전체 |
| 1 | 서울 | 2015 | 10 | 5652.0 | 18651.6 | 60㎡ |
| 2 | 서울 | 2015 | 10 | 5882.0 | 19410.6 | 60㎡~ 85㎡ |
| 3 | 서울 | 2015 | 10 | 5721.0 | 18879.3 | 85㎡~ 102㎡ |
| 4 | 서울 | 2015 | 10 | 5879.0 | 19400.7 | 102㎡~ |
# melt로 데이터형태를 바꿔서 같은 형태로 만들어주기
df_first_melt = df_first.melt(id_vars="지역", var_name="기간", value_name="평당분양가격")
# 지역만 칼럼으로 쓰고 나머지는 행으로 녹인다.
# var_name으로 variable 칼럼이름을 바꿔준다.
# value_name으로 평당분양가격으로 아름 바꿔줌
df_first_melt.head()
| 지역 | 기간 | 평당분양가격 | |
|---|---|---|---|
| 0 | 서울 | 2013년12월 | 18189 |
| 1 | 부산 | 2013년12월 | 8111 |
| 2 | 대구 | 2013년12월 | 8080 |
| 3 | 인천 | 2013년12월 | 10204 |
| 4 | 광주 | 2013년12월 | 6098 |
df_first_melt.columns = ["지역명", "기간", "평당분양가격"]
# columns로 칼럼이름 변경
df_first_melt.head()
| 지역명 | 기간 | 평당분양가격 | |
|---|---|---|---|
| 0 | 서울 | 2013년12월 | 18189 |
| 1 | 부산 | 2013년12월 | 8111 |
| 2 | 대구 | 2013년12월 | 8080 |
| 3 | 인천 | 2013년12월 | 10204 |
| 4 | 광주 | 2013년12월 | 6098 |
# 기간에 있는 연도, 월을 빼고 칼럼으로 만들기
#년도 반환 함수
def parse_year(date):
year = date.split("년")[0] # 년기준 앞
year = int(year) # object를 int로 바꿔줌
return year
date = "2013년12월"
parse_year(date)
2013
#월 반환 함수
def parse_month(date):
month = date.split("년")[-1].replace("월", "") # 년기준 맨 뒤
month = int(month) # object를 int로 바꿔줌
return month
parse_month(date)
12
df_first_melt["연도"] = df_first_melt["기간"].apply(parse_year) # 앞에서만든 parse_year함수 적용(apply)
df_first_melt.head()
| 지역명 | 기간 | 평당분양가격 | 연도 | |
|---|---|---|---|---|
| 0 | 서울 | 2013년12월 | 18189 | 2013 |
| 1 | 부산 | 2013년12월 | 8111 | 2013 |
| 2 | 대구 | 2013년12월 | 8080 | 2013 |
| 3 | 인천 | 2013년12월 | 10204 | 2013 |
| 4 | 광주 | 2013년12월 | 6098 | 2013 |
df_first_melt["월"] = df_first_melt["기간"].apply(parse_month)
df_first_melt.head()
| 지역명 | 기간 | 평당분양가격 | 연도 | 월 | |
|---|---|---|---|---|---|
| 0 | 서울 | 2013년12월 | 18189 | 2013 | 12 |
| 1 | 부산 | 2013년12월 | 8111 | 2013 | 12 |
| 2 | 대구 | 2013년12월 | 8080 | 2013 | 12 |
| 3 | 인천 | 2013년12월 | 10204 | 2013 | 12 |
| 4 | 광주 | 2013년12월 | 6098 | 2013 | 12 |
두개의 데이터프레임 합치기
df_last[df_last["전용면적"] == "전체"]
#불리언인덱싱으로 전용면적이 전체인것만 가져오기
| 지역명 | 연도 | 월 | 분양가격 | 평당분양가격 | 전용면적 | |
|---|---|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 5841.0 | 19275.3 | 전체 |
| 5 | 인천 | 2015 | 10 | 3163.0 | 10437.9 | 전체 |
| 10 | 경기 | 2015 | 10 | 3138.0 | 10355.4 | 전체 |
| 15 | 부산 | 2015 | 10 | 3112.0 | 10269.6 | 전체 |
| 20 | 대구 | 2015 | 10 | 2682.0 | 8850.6 | 전체 |
| ... | ... | ... | ... | ... | ... | ... |
| 4310 | 전북 | 2019 | 12 | 2468.0 | 8144.4 | 전체 |
| 4315 | 전남 | 2019 | 12 | 2452.0 | 8091.6 | 전체 |
| 4320 | 경북 | 2019 | 12 | 2914.0 | 9616.2 | 전체 |
| 4325 | 경남 | 2019 | 12 | 3063.0 | 10107.9 | 전체 |
| 4330 | 제주 | 2019 | 12 | 3882.0 | 12810.6 | 전체 |
867 rows × 6 columns
df_last.columns.to_list()
#리스트형태로 바꾸기
['지역명', '연도', '월', '분양가격', '평당분양가격', '전용면적']
cols = ['지역명', '연도', '월', '평당분양가격']
# 필요한 칼럼만 뽑기
df_last_prepare = df_last.loc[df_last["전용면적"] == "전체",
cols].copy()
# 필요한 칼럼만저장
df_last_prepare
| 지역명 | 연도 | 월 | 평당분양가격 | |
|---|---|---|---|---|
| 0 | 서울 | 2015 | 10 | 19275.3 |
| 5 | 인천 | 2015 | 10 | 10437.9 |
| 10 | 경기 | 2015 | 10 | 10355.4 |
| 15 | 부산 | 2015 | 10 | 10269.6 |
| 20 | 대구 | 2015 | 10 | 8850.6 |
| ... | ... | ... | ... | ... |
| 4310 | 전북 | 2019 | 12 | 8144.4 |
| 4315 | 전남 | 2019 | 12 | 8091.6 |
| 4320 | 경북 | 2019 | 12 | 9616.2 |
| 4325 | 경남 | 2019 | 12 | 10107.9 |
| 4330 | 제주 | 2019 | 12 | 12810.6 |
867 rows × 4 columns
df_first_prepare = df_first_melt[cols].copy()
df_first_prepare.head()
| 지역명 | 연도 | 월 | 평당분양가격 | |
|---|---|---|---|---|
| 0 | 서울 | 2013 | 12 | 18189 |
| 1 | 부산 | 2013 | 12 | 8111 |
| 2 | 대구 | 2013 | 12 | 8080 |
| 3 | 인천 | 2013 | 12 | 10204 |
| 4 | 광주 | 2013 | 12 | 6098 |
# concat으로 두개의 데이터를 합치기
df = pd.concat([df_first_prepare, df_last_prepare])
df
#df.shape
| 지역명 | 연도 | 월 | 평당분양가격 | |
|---|---|---|---|---|
| 0 | 서울 | 2013 | 12 | 18189.0 |
| 1 | 부산 | 2013 | 12 | 8111.0 |
| 2 | 대구 | 2013 | 12 | 8080.0 |
| 3 | 인천 | 2013 | 12 | 10204.0 |
| 4 | 광주 | 2013 | 12 | 6098.0 |
| ... | ... | ... | ... | ... |
| 4310 | 전북 | 2019 | 12 | 8144.4 |
| 4315 | 전남 | 2019 | 12 | 8091.6 |
| 4320 | 경북 | 2019 | 12 | 9616.2 |
| 4325 | 경남 | 2019 | 12 | 10107.9 |
| 4330 | 제주 | 2019 | 12 | 12810.6 |
1224 rows × 4 columns
df.shape
(1224, 4)
df["연도"].value_counts(sort=False)
2013 17
2014 204
2015 187
2016 204
2017 204
2018 204
2019 204
Name: 연도, dtype: int64
pivot_table로 heatmap 표현
#연도를 인덱스로, 지역명을 컬러믕로 평당분양가격을 피봇테일블로
t = pd.pivot_table(df, index="연도", columns="지역명",
values="평당분양가격").round()
t
| 지역명 | 강원 | 경기 | 경남 | 경북 | 광주 | 대구 | 대전 | 부산 | 서울 | 세종 | 울산 | 인천 | 전남 | 전북 | 제주 | 충남 | 충북 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 연도 | |||||||||||||||||
| 2013 | 6230.0 | 10855.0 | 6473.0 | 6168.0 | 6098.0 | 8080.0 | 8321.0 | 8111.0 | 18189.0 | 7601.0 | 8090.0 | 10204.0 | 5678.0 | 6282.0 | 7674.0 | 6365.0 | 6589.0 |
| 2014 | 6332.0 | 10509.0 | 6729.0 | 6536.0 | 7588.0 | 8286.0 | 8240.0 | 9180.0 | 18997.0 | 8085.0 | 8362.0 | 10075.0 | 5719.0 | 6362.0 | 7855.0 | 6682.0 | 6620.0 |
| 2015 | 6831.0 | 10489.0 | 7646.0 | 7035.0 | 7956.0 | 8707.0 | 8105.0 | 9633.0 | 19283.0 | 8641.0 | 9273.0 | 10277.0 | 6109.0 | 6623.0 | 7465.0 | 7024.0 | 6700.0 |
| 2016 | 7011.0 | 11220.0 | 7848.0 | 7361.0 | 8899.0 | 10310.0 | 8502.0 | 10430.0 | 20663.0 | 8860.0 | 10209.0 | 10532.0 | 6489.0 | 6418.0 | 9129.0 | 7331.0 | 6770.0 |
| 2017 | 7127.0 | 11850.0 | 8120.0 | 7795.0 | 9464.0 | 11456.0 | 9045.0 | 11578.0 | 21376.0 | 9135.0 | 11345.0 | 10737.0 | 7188.0 | 7058.0 | 10831.0 | 7456.0 | 6763.0 |
| 2018 | 7681.0 | 13186.0 | 9019.0 | 8505.0 | 9856.0 | 12076.0 | 10180.0 | 12998.0 | 22889.0 | 10355.0 | 10241.0 | 11274.0 | 7789.0 | 7626.0 | 11891.0 | 8013.0 | 7874.0 |
| 2019 | 8142.0 | 14469.0 | 9871.0 | 8857.0 | 11823.0 | 13852.0 | 11778.0 | 13116.0 | 26131.0 | 11079.0 | 10022.0 | 12635.0 | 7902.0 | 8197.0 | 12138.0 | 8607.0 | 7575.0 |
plt.figure(figsize=(15, 7))
sns.heatmap(t, cmap="Blues", annot=True, fmt=".0f")
# cmap으로 색 지정
# annot으로 수치 표현
#fmt로 수치가 잘보이게 표현(소수점 없이)
#서울이 가장 높다.
<matplotlib.axes._subplots.AxesSubplot at 0x171ec2a15e0>
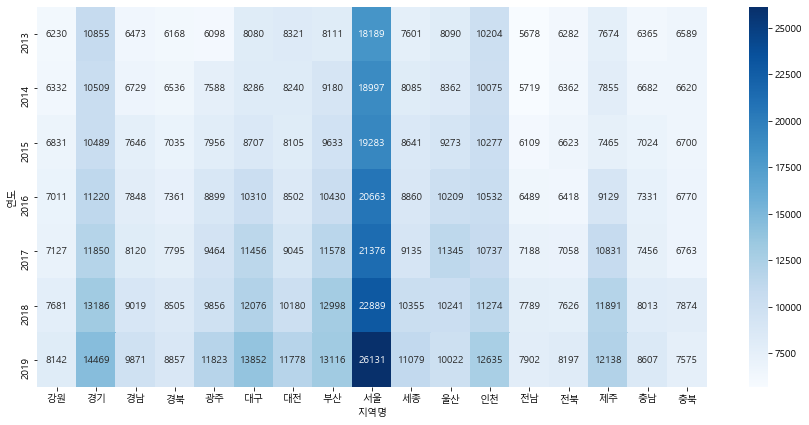
# T는 transpose로 행과 열을 바꿔준다.
#t.T
t.transpose()
| 연도 | 2013 | 2014 | 2015 | 2016 | 2017 | 2018 | 2019 |
|---|---|---|---|---|---|---|---|
| 지역명 | |||||||
| 강원 | 6230.0 | 6332.0 | 6831.0 | 7011.0 | 7127.0 | 7681.0 | 8142.0 |
| 경기 | 10855.0 | 10509.0 | 10489.0 | 11220.0 | 11850.0 | 13186.0 | 14469.0 |
| 경남 | 6473.0 | 6729.0 | 7646.0 | 7848.0 | 8120.0 | 9019.0 | 9871.0 |
| 경북 | 6168.0 | 6536.0 | 7035.0 | 7361.0 | 7795.0 | 8505.0 | 8857.0 |
| 광주 | 6098.0 | 7588.0 | 7956.0 | 8899.0 | 9464.0 | 9856.0 | 11823.0 |
| 대구 | 8080.0 | 8286.0 | 8707.0 | 10310.0 | 11456.0 | 12076.0 | 13852.0 |
| 대전 | 8321.0 | 8240.0 | 8105.0 | 8502.0 | 9045.0 | 10180.0 | 11778.0 |
| 부산 | 8111.0 | 9180.0 | 9633.0 | 10430.0 | 11578.0 | 12998.0 | 13116.0 |
| 서울 | 18189.0 | 18997.0 | 19283.0 | 20663.0 | 21376.0 | 22889.0 | 26131.0 |
| 세종 | 7601.0 | 8085.0 | 8641.0 | 8860.0 | 9135.0 | 10355.0 | 11079.0 |
| 울산 | 8090.0 | 8362.0 | 9273.0 | 10209.0 | 11345.0 | 10241.0 | 10022.0 |
| 인천 | 10204.0 | 10075.0 | 10277.0 | 10532.0 | 10737.0 | 11274.0 | 12635.0 |
| 전남 | 5678.0 | 5719.0 | 6109.0 | 6489.0 | 7188.0 | 7789.0 | 7902.0 |
| 전북 | 6282.0 | 6362.0 | 6623.0 | 6418.0 | 7058.0 | 7626.0 | 8197.0 |
| 제주 | 7674.0 | 7855.0 | 7465.0 | 9129.0 | 10831.0 | 11891.0 | 12138.0 |
| 충남 | 6365.0 | 6682.0 | 7024.0 | 7331.0 | 7456.0 | 8013.0 | 8607.0 |
| 충북 | 6589.0 | 6620.0 | 6700.0 | 6770.0 | 6763.0 | 7874.0 | 7575.0 |
plt.figure(figsize=(15, 7))
sns.heatmap(t.T, cmap="Blues", annot=True, fmt=".0f")
<matplotlib.axes._subplots.AxesSubplot at 0x171ec2a1160>
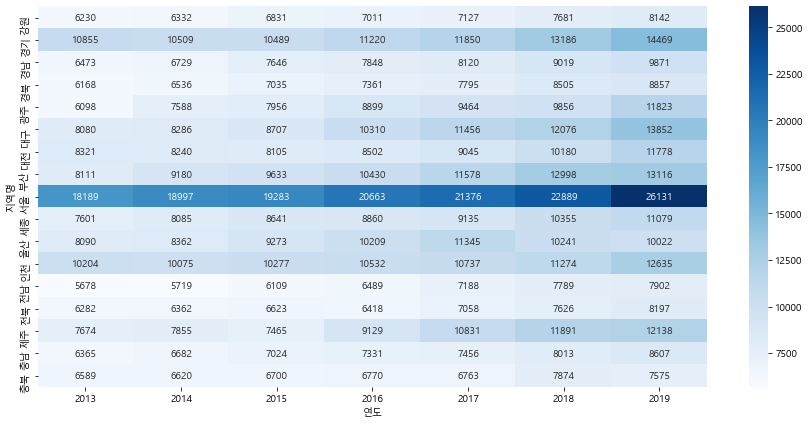
g = df.groupby(["연도","지역명"])["평당분양가격"].mean().unstack().round()
# unstack이용하면 마지막 인덱스값이(지역명) 칼럼으로 간다
#round는 소수점 1자리 까지
plt.figure(figsize=(15, 7))
sns.heatmap(g.T, annot=True, fmt=".0f", cmap="Greens")
#fmt=".0f" 소수점 없이 표현
<matplotlib.axes._subplots.AxesSubplot at 0x171eee59a30>
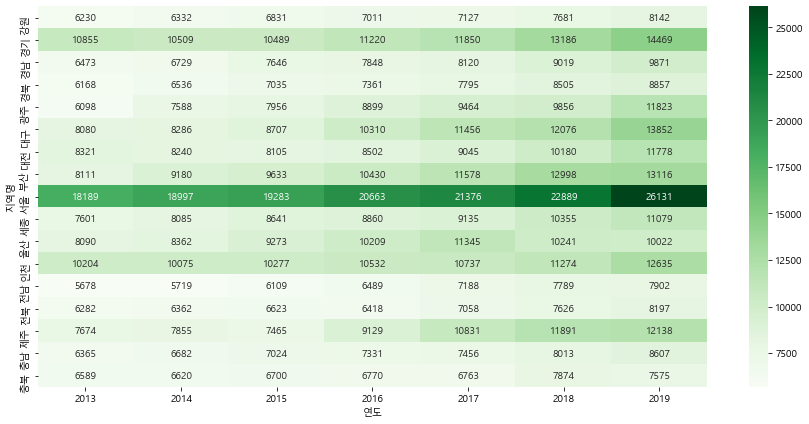
2013년부터 최근 데이터까지 시각화
# barplot으로 연도별 평당분양가격 그리기
sns.barplot(data=df, x="연도", y="평당분양가격", ci=None)
<matplotlib.axes._subplots.AxesSubplot at 0x171ef342520>
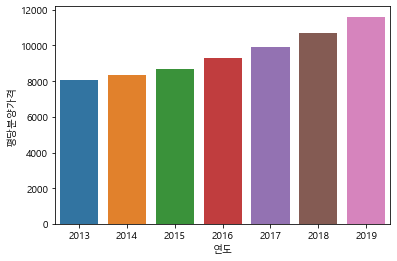
# pointplot으로 연도별 평당분양가격 그리기
plt.figure(figsize=(12, 4))
sns.pointplot(data=df, x="연도", y="평당분양가격", hue="지역명")
# 범례(legend) 밖으로 빼기
plt.legend(bbox_to_anchor=(1.02, 1), loc=2, borderaxespad=0.)
<matplotlib.legend.Legend at 0x171ef3774c0>
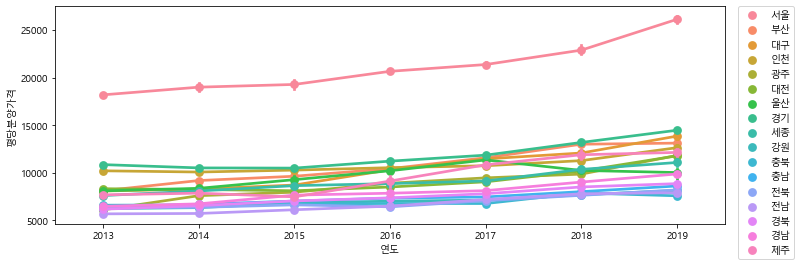
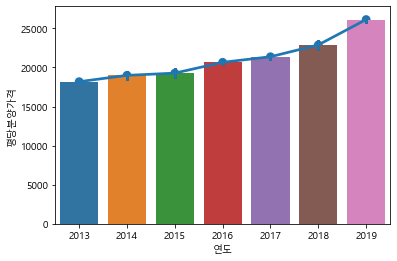
# 서울만 barplot으로 그리기
df_seoul = df[df["지역명"] == "서울"].copy()
#df_seoul.shape
sns.barplot(data=df_seoul, x="연도", y="평당분양가격")
sns.pointplot(data=df_seoul, x="연도", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171ef5140d0>
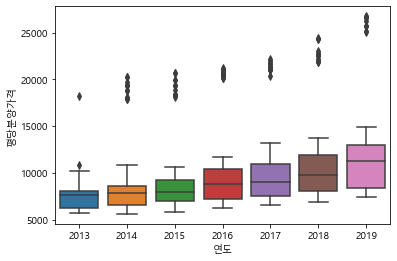
#연도별 평당분양가격 boxplot 그리기
sns.boxplot(data=df ,x ="연도", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171ef7ab220>
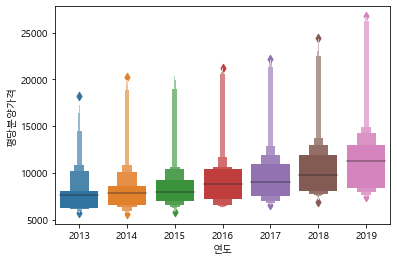
#연도별 평당분양가격 boxenplot 그리기
sns.boxenplot(data=df ,x ="연도", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171ef872c40>
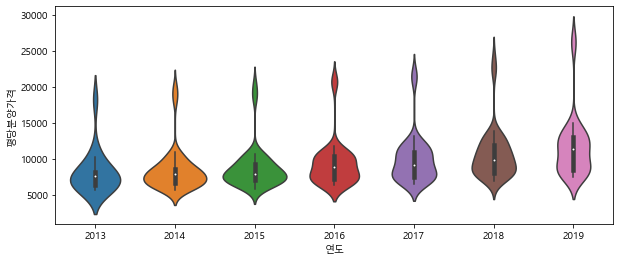
#연도별 평당분양가격 violinplot 그리기
plt.figure(figsize=(10, 4))
sns.violinplot(data=df ,x ="연도", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171ef907250>
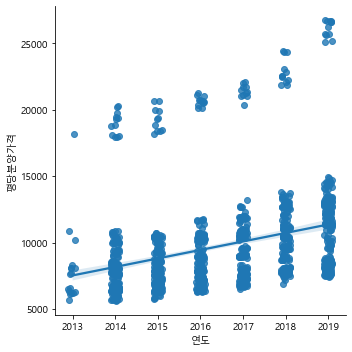
#연도별 평당분양가격 lmplot 그리기
plt.figure(figsize=(10, 4))
sns.lmplot(data=df ,x ="연도", y="평당분양가격", x_jitter=.1)
<seaborn.axisgrid.FacetGrid at 0x171ef99dee0>
<Figure size 720x288 with 0 Axes>
지역별 평당분양가격 보기
# barplot으로 지역별 평당분양가격을 그리기
plt.figure(figsize=(12, 4))
sns.barplot(data=df, x="지역명", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171ef9f3340>
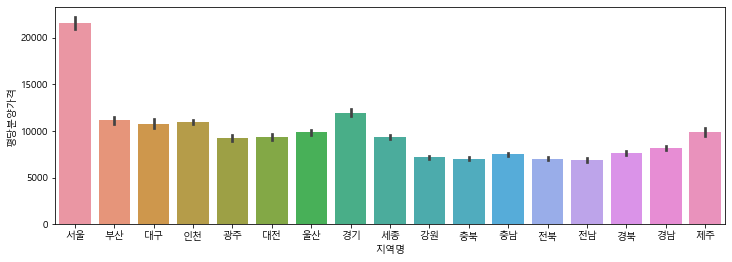
# boxenplot으로 지역별 평당분양가격을 그리기
plt.figure(figsize=(12, 4))
sns.boxenplot(data=df, x="지역명", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171efaa83d0>
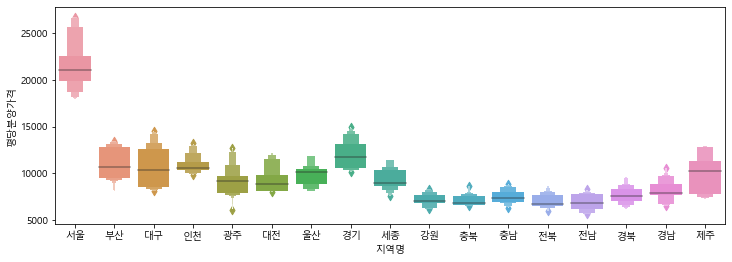
# violinplot으로 지역별 평당분양가격을 그리기
plt.figure(figsize=(24, 4))
sns.violinplot(data=df, x="지역명", y="평당분양가격")
<matplotlib.axes._subplots.AxesSubplot at 0x171efbab550>

